



혁신으로 세상을 바꾸는 융복합 대학, DGIST
혁신으로 세상을 바꾸는 융복합 대학, DGIST
혁신으로 세상을 바꾸는 융복합 대학, DGIST
혁신으로 세상을 바꾸는 융복합 대학, DGIST



Research




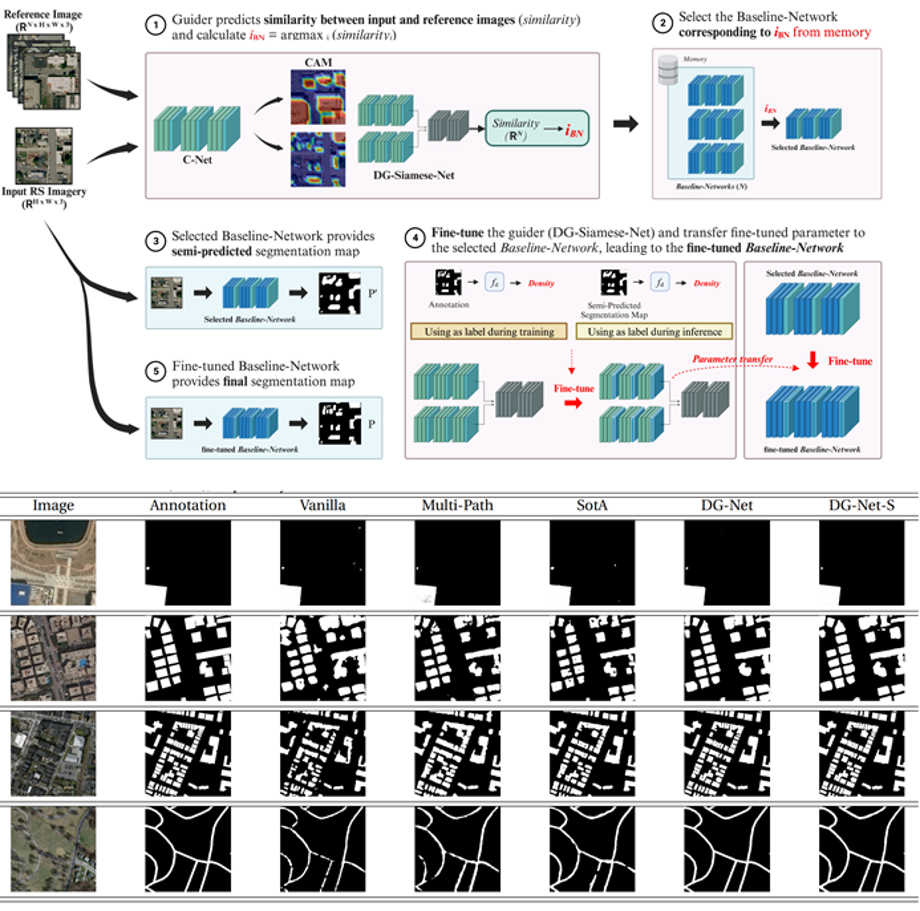
Education &
Research DGIST는 과학기술정보통신부 소속으로 2004년 국책연구기관으로 출범,
2011년 석·박사 과정 개설, 2014년 학사과정 개설로 교육과 연구 기능이
공존하는 국내 유일의 교육·연구기관입니다.
Research DGIST는 과학기술정보통신부 소속으로 2004년 국책연구기관으로 출범,
2011년 석·박사 과정 개설, 2014년 학사과정 개설로 교육과 연구 기능이
공존하는 국내 유일의 교육·연구기관입니다.

Announcement & Updates


